I have been doing “Agile development” for more than 5 years. I am used to saying that an organization is Agile at the level of its weakest element. So I cannot claim having worked on any fully Agile projects. However, I have always tried to apply as many as possible Agile principles to my work. This blog entry goes over different practices and identifies the ones that worked best for me and my teams.
Agile
The Agile methodology is a not pure invention, this is the compilation of best directives gathered from various practices:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
Scrum
“Scrum is a lightweight Iterative and Incremental (Agile) Development Method that focuses on delivering rapidly the highest priority features based on business value.” It has been defined by Ken Schwaber and Jeff Sutherland in early 1990s.
Scrum promotes high collaboration and transparency. There are different backlogs helping delivering the best business values at each iteration. Capturing and integrating feedback (from business users, stakeholders, developers, testers, etc.) is a recurrent task. Deliveries occur often and their progression is continuously monitored.
Scrum in Under 10 Minutes by Hamid Shojaee
The points I really like about Scrum:
- Task reviews done with all actors, in Poker Planning [2] sessions, for example.
- Product designed, coded AND tested during the Sprint.
- Sprint deliveries are workable products, with limited/disabled features, but working without blocking issues.
- Defined roles: Product Owner, Scrum Master (aka Project Manager), and Project Team (composed of cross-functional skills: dev., QA, DBA, Rel. Eng., etc.).
eXtreme Programming
While Scrum is mainly managers (chicken) oriented, eXtreme Programming (XP) focuses more on do-ers (pigs).
XP is more a matter of having the right tools and having real technical exchanges within the Scrum team. For example, XP strongly suggests the adoption of peer-programming: two developers per computers, one coding and the other thinking about the coding and correcting the code on-the-fly.
Applying peer programming in teams with actors from various backgrounds is sometimes too constraining. Matching peers is a difficult exercise. However, enforcing peer code reviews allows to get almost the same benefits without too much frustration. With code reviews, junior developers can see seniors' work in action, and senior developers can learn new programming paradigms. I found it's good also for the team cohesion, because team members really know about each others' work.
Among the practices XP incites to follow, there are:
- Continuous Integration: every time a developer or a tester delivers new materials, a complete build process starts to compile, package and test the entire application. Ideally, the build time is short enough to prevent committers to start any other tasks, so they can fix it right away. A safe strategy is to put “fixing the build” as the top priority whenever a problem occurs.
- Unit testing and code coverage: when developers write unit tests, they provide the first piece of code consuming their own code, and experience shows that it really helps delivering better code. Unit tests without code coverage measurements does not mean much. And not trying to reach 100% coverage leaves too much space to defective code... Using mock objects [4] is an essential tool to test accurately. Test Driven Development (TDD) methodology is pushing this practice up to writing the tests before the code.
- Continuous refactoring: during each sprint, developers should focus on the immediate requirements, because they have very little control on future sprints (the product owner can adjust the development plan anytime). This is sometimes difficult to limit them to their immediate tasks because many do not like the perspective of having to rewrite their code later. Investing in tools like IntelliJ IDEA which provides extended refactoring features is really worth it because developers can adapt their code efficiently while being secured by the continuously growing regression test suites.
Best of both approaches
In medium to big companies, they are often many layers of management. In such environments, when managers should be facilitators[5], they often add weight to the processes.
About the issues in shipped products, here is an anecdote about IBM:
Development labs are often known for delivering over the budget, over the allocated time, and with too many issues. Many times, I have seen the maintenance being operated by specific teams, without relation with the development ones. In such environments, development teams focus on delivering features and maintenance teams fix issues: each team has its own budget and life goes on!An internal team reviewed the quality of the released products and came to the initial conclusion that minor and maintenance releases contain more flaws than major releases. The conclusion was made after studying the number of defects reported by customers: this number was sometimes twice higher for intermediate releases. But the team pushed its investigation further and polled many customers. At the end, it appears that very few customers were installing major releases immediately, most of them would wait for the first maintenance release to deploy in pre-production environments (one stage before production one).In this story, IBM used the results of this study to size and train the support teams according to the product release plans. As you can expect, more support people are trained and made available on releases following major ones. It did not help IBM delivering better products up front, it mostly smoothed the experience of customers reporting problems ;)
The combination of the relatively poor delivered software, the accumulation of managers, and the Scrum burn-down chart (the chart that shows how the work progress on a daily basis [6]) favors Scrum adoption in IT organizations.

Burn down chart sample
My problem with Scrum as I see it in action is related to its usage by managers: it is a one-way communication channel for them to put the pressure on Scrum teams. And because Scrum is task oriented, if the task set is incomplete (or deliberately cut through), these managers mostly follow the feature completion rate, and sometimes the defect detection and fixing rates.
In my experience, with organizations transitioning from waterfall methodologies to Scrum, the feature check list has always precedence on the quality check list! If tasks have a risk to break the deadline, the test efforts are cut. And because these organizations have very few ways to measure the delivered quality (because they adopted Scrum but refused to invest in XP), results are not really better for customers...
This is why I think it is important to balance the importance of Scrum with the one of XP, why as the same time managers should tools to monitor the work progress, Scrum teams should publish quality metrics about all delivered pieces of code. With both sides being instrumented, it is be easier to identify decision impacts and product owners can make informed decisions.
A+, Dom
--
Sources:
- Principles of the Agile Manifesto, and definition of Agile methodology on Wikipedia.
- Description of Poker Planing on Wikipedia.
- The Classic Story of the Chicken and Pig on ImplementingScrum.com, and the role definition by Nick Malik.
- Mock object definition on Wikipedia, and Chapter 7: Testing in isolation with mock objects from the book JUnit In Action, by Vincent Massol.
- My personal view on the facilitator role managers should have: Manager Attitude.
- Burn-down chart described as a Scrum artifact on Wikipedia and Burn Baby Burn on ImplementingScrum.com.

 Once I decided to go with GAE, I invested a bit in improving my knowledge of Python [4], for example by looking at the WSGI specification [4] and at Django [4]. I have been impressed about the integration done by GAE people, about how easy it is to program complex steps in very few lines! My favorite part is the main function to dispatching events:
Once I decided to go with GAE, I invested a bit in improving my knowledge of Python [4], for example by looking at the WSGI specification [4] and at Django [4]. I have been impressed about the integration done by GAE people, about how easy it is to program complex steps in very few lines! My favorite part is the main function to dispatching events: In the J2EE world, with the
In the J2EE world, with the 






 Google App Engine (GAE) [1] is an open platform made available by Google to host Web applications:
Google App Engine (GAE) [1] is an open platform made available by Google to host Web applications: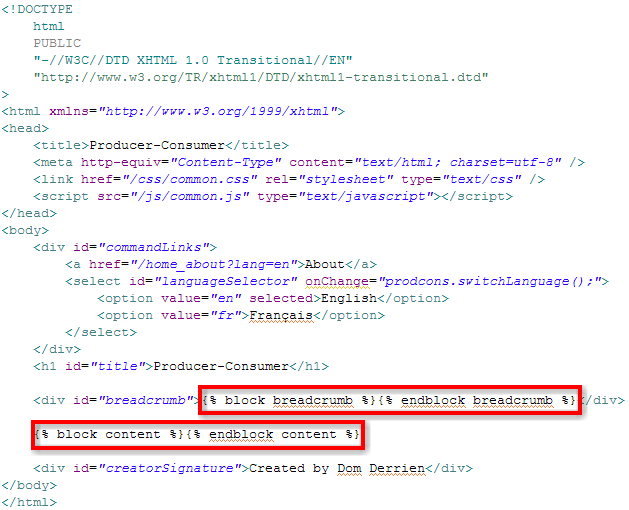
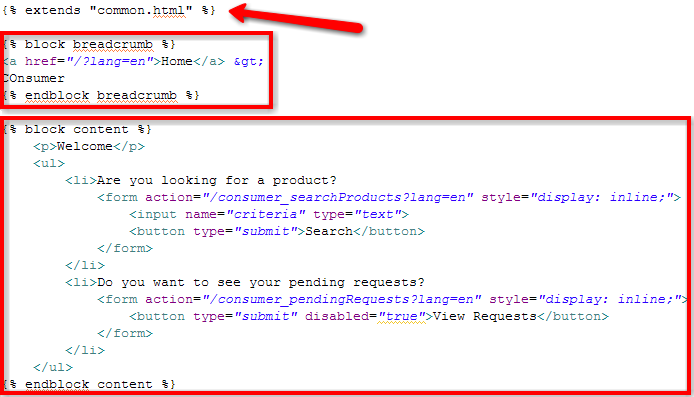
 When searching information to test Google App Engine (GAE) applications, I was happy to find a post [3] written by Josh Cronemeyer who says:
When searching information to test Google App Engine (GAE) applications, I was happy to find a post [3] written by Josh Cronemeyer who says:


 But subversion has limitations, like the importance of the connectivity with the subversion server whenever you want to gain access a file history or to revert an update. Because I have just started a new side project [3], I have decided to go with git and the hosting service
But subversion has limitations, like the importance of the connectivity with the subversion server whenever you want to gain access a file history or to revert an update. Because I have just started a new side project [3], I have decided to go with git and the hosting service 