In my initial article, I explained some hurdles of globalizing applications, especially the ones being implemented with many programming languages. In this article, I'm going to describe few use-cases and how my open-source library two-tiers-utils can ease the implementation. Here are the covered topics:
- Get the user's preferred locale
- Display messages in different locales
- Handle localized messages with different programming languages
- Generate the localized bundles per programming language
- Bonus
For this use-case, let's only consider the Java programming language. Another assumption is the availability of the localized resources in the corresponding Java format (i.e. accessible via a PropertyResourceBundle instance).
In a Web application, the user's preferred locale can be retrieved from:
- The HTTP headers:
locale = ((HttpServletRequest) request).getLocale();
- The HTTP session (if saved there previously):
HttpSession session = ((HttpServletRequest) request).getSession(false); if (session != null) { locale = new Locale((String) session.getAttribute(SESSION_USER_LOCALE_ID)); } - The record containing the user's information:
locale = ((UserDTO) user).getPreferredLocale();
domderrien.i18n.LocaleController classExcerpt of public methods offered within
domderrien.i18n.LocaleController
This class can be used in two situations:
- In a login form, for example, when we can just guess the desired locale from the browser preferred language list or from an argument in the URL.
- In pages accessible to identified users thanks to the HTTP session.
Usage example of the
domderrien.i18n.LocaleController.detectLocale()<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<%@page
language="java"
contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"
import="org.domderrien.i18n.LabelExtractor"
import="org.domderrien.i18n.LocaleController"
%><%
// Locale detection
Locale locale = LocaleController.detectLocale(request);
%><html>
<head>
<title><%= LabelExtractor.get("dd2tu_applicationName", locale) %></title>
...
</head>
<body>
...
<img
class="anchorLogo"
src="images/iconHelp.png"
width="16"
height="16"
title="<%= LabelExtractor.get("dd2tu_topCommandBox_helpIconLabel", locale) %>"
/>
...
</body>
</html>The previous example introduces also a second class:
domderrien.i18n.LabelExtractor. Being given an identifier, an optional array of Object references, and a locale, the get static method loads the corresponding string from the localized resource bundle.Excerpt of public methods offered within domderrien.i18n.LabelExtractor
 A series of localized entries like
A series of localized entries like en:“Welcome {0} {1}”, fr:“Bonjour {2} {1}”, and ja:“お早う {0}{1}” can be easily invoked with a simple command like: LabelExtractor.get("welcome_message", new Object[] { user.getFirstName(), user.getLastName() }, user.getLocale());.Java is a pretty neat language with a large set of editors and code inspectors. But Java is not the only languages used for Web applications. If the two-tiers-utils library provides nice Java features, the delivery of the same library interfaces for the programming languages JavaScript and Python libraries makes it way more valuable!
Code of the
domderrien.i18n.LabelExtractor.get() method for the JavaScript language.(function() { // To limit the scope of the private variables
/**
* @author dom.derrien
* @maintainer dom.derrien
*/
var module = dojo.provide("domderrien.i18n.LabelExtractor");
var _dictionnary = null;
module.init = function(/*String*/ namespace, /*String*/ filename, /*String*/ locale) {
// Dojo uses dash-separated (e.g en-US not en_US) and uses lower case names (e.g en-us not en_US)
locale = (locale || dojo.locale).replace('_','-').toLowerCase();
// Load the bundle
try {
// Notes:
// - Cannot use the notation "dojo.requirelocalization" because dojo parser
// will try to load the bundle when this file is interpreted, instead of
// waiting for a call with meaningful "namespace" and "filename" values
dojo["requireLocalization"](namespace, filename, locale); // Blocking call getting the file per XHR or <iframe/>
_dictionary = dojo.i18n.getLocalization(namespace, filename, locale);
}
catch(ex) {
alert("Deployment issue:" +
"\nCannot get localized bundle " + namespace + "." + filename + " for the locale " + locale +
"\nMessage: " + ex
);
}
return module;
};
module.get = function(/*String*/key, /*Array*/args) {
if (_dictionary == null) {
return key;
}
var message = _dictionary[key] || key;
if (args != null) {
dojo.string.substituteParams(message, args);
}
return message;
};
})(); // End of the function limiting the scope of the private variablesThe following piece of code illustrates how the JavaScript
domderrien.i18n.LabelExtractor class instance should be initialized (the value of the locale variable can come from dojo.locale or a value injected server-side into a JSP page) and how it can be invoked to get a localized label.Usage example of the
domderrien.i18n.LocaleController.get()(function() { // To limit the scope of the private variables
var module = dojo.provide("domderrien.blog.Test");
dojo.require("domderrien.i18n.LabelExtractor");
var _labelExtractor;
module.init = function(/*String*/ locale) {
// Get the localized resource bundle
_labelExtractor = domderrien.i18n.LabelExtractor.init(
"domderrien.blog",
"TestBundle",
locale // The library is going to fallback on dojo.locale if this parameter is null
);
...
};
module._postData = function(/*String*/ url, /*Object*/ jsonParams) {
var transaction = dojo.xhrPost({
content : jsonParams,
handleAs : "json",
load : function(/*object*/ response, /*Object*/ioargs) {
if (response == null) {
// Message prepared client-side
_reportError(_labelExtractor.get("dd2tu_xhr_unexpectedError"), [ioargs.xhr.status]);
}
if (!response.success) {
// Message prepared server-side
_reportError(_labelExtractor.get(response.messageKey), response.msgParams);
}
...
},
error : function(/*Error*/ error, /*Object*/ ioargs) {
// Message prepared client-side
_reportError(error.message, [ioargs.xhr.status]);
},
url : url
});
};
var _reportError = function(/*String*/ message, /*Number ?*/xhrStatus) {
var console = dijit.byId("errorConsole");
...
};
...
})(); // End of the function limiting the scope of the private variablesThe following series of code excerpts show the pieces involved in getting the localized resources with the Python programming language.
LabelExtractor methods definitions from
domderrien/i18n/LabelExtractor.py# -*- coding: utf-8 -*-
import en
import fr
def init(locale):
"""Initialize the global dictionary for the specified locale"""
global dict
if locale == "fr":
dict = fr._getDictionary()
else: # "en" is the default language
dict = en._getDictionary()
return dictSample of a localized dictionary from
domderrien/i18n/en.py# -*- coding: utf-8 -*-
dict_en = {}
def _getDictionary():
global dict_en
if (len(dict_en) == 0):
_fetchDictionary(dict_en)
return dict_en
def _fetchDictionary(dict):
dict["_language"] = "English"
dict["dd2tu_applicationName"] = "Test Application"
dict["dd2tu_welcomeMsg"] = "Welcome {0}."
...Definitions of filters used by the Django templates, from
domderrien/i18n/filters.pyfrom google.appengine.ext import webapp
def get(dict, key):
return dict[key]
def replace0(pattern, value0):
return pattern.replace("{0}", str(value0))
def replace1(pattern, value1):
return pattern.replace("{1}", str(value1))
...
# http://javawonders.blogspot.com/2009/01/google-app-engine-templates-and-custom.html
# http://daily.profeth.de/2008/04/using-custom-django-template-helpers.html
register = webapp.template.create_template_register()
register.filter(get)
register.filter(replace0)
register.filter(replace1)
...Django template from
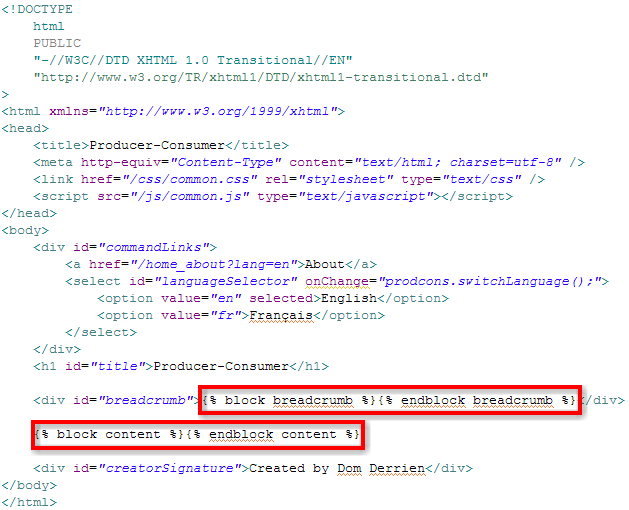
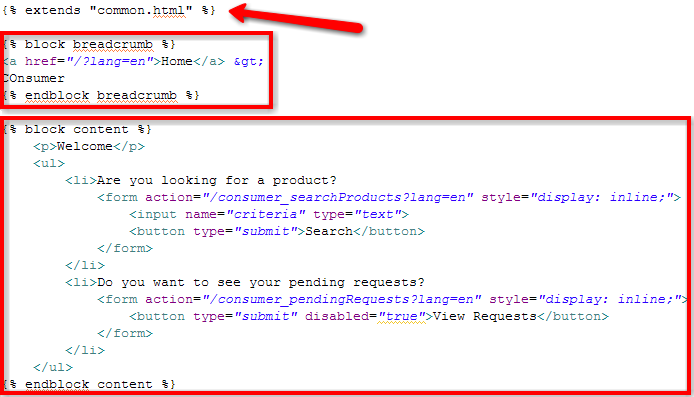
domderrien/blog/Test.html<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>{{ dictionary|get:dd2tu_applicationName }}</title>
....
</head>
<body>
...
<div class="...">{{ dictionary|get:dd2tu_welcomeMsg|replace0:parameters.loggedUser }}</div>
...
</body>
</html>Test handler from
domderrien/blog/Test.pyfrom google.appengine.api import users
from google.appengine.ext import webapp
from google.appengine.ext.webapp import template
def prepareDictionary(Request):
locale = request.get('lang', 'en')
return LabelExtractor.init(locale)
class MainPage(webapp.RequestHandler):
def get(self):
parameters = {}
parameters ['dictionary'] = domderrien.i18n.LabelExtractor.init(self.request)
parameters ['loggedUser'] = users.get_current_user()
path = os.path.join(os.path.dirname(__file__), 'domderrien/blog/Test.html')
self.response.out.write(template.render(path, parameters))
application = webapp.WSGIApplication(
[('/', MainPage)],
debug=True
)
def main():
webapp.template.register_template_library('domderrien.i18n.filters')
run_wsgi_app(application)
if __name__ == "__main__":
main()In my previous post Internationalization of GAE applications, I suggest to use a dictionary format that would be programming lnaguage agnostic while being known by translator: TMX, for Tanslation Memory eXchange.
Snippet of a translation unit definition for a TMX formatted file
<tu tuid="dd2tu_welcomeMessage" datatype="Text">
<tuv xml:lang="en">
<seg>Welcome {0}</seg>
</tuv>
<note>{0} is going to be replaced by the logged user's display name</note>
<prop type="x-tier">dojotk</prop>
<prop type="x-tier">javarb</prop>
<prop type="x-tier">python</prop>
</tu>The two-tiers-utils library provides a Java runtime
domderrien.build.TMXConverter that generates the resource bundles for Java/JavaScript/Python. If a simple series of XSL-Transform runs can do the job, the TMXConverter does a bit more by:- Comparing the modification dates of the generated files with the TMX one to generate them only if needed
- Check the uniqueness of the label keys
- Generate the list of supported languages
TMXConverter runtime from an ant build file is very simple, while a bit verbose:Ant target definition invoking the TMXConverter<target name="step-tmx-convert">
<mkdir dir="${temp.dir}/resources" />
<mkdir dir="src/WebContent/js/domderrien/i18n/nls" />
<java classname="domderrien.build.TMXConverter" fork="true" failonerror="true">
<classpath refid="tmxconverter.classpath" />
<classpath location="${temp.dir}/resources" />
<jvmarg value="-Dfile.encoding=UTF-8" />
<arg value="-tmxFilenameBase" />
<arg value="${dd2tu.localizedLabelBaseFilename}" />
<arg value="-sourcePath" />
<arg value="${basedir}\src\resources" />
<arg value="-jsDestPath" />
<arg value="${basedir}\src\WebContent\js\domderrien\i18n\nls" />
<arg value="-javaDestPath" />
<arg value="${temp.dir}/resources" />
<arg value="-languageFilenameBase" />
<arg value="${dd2tu.languageListFilename}" />
<arg value="-buildStamp" />
<arg value="${dd2tu.stageId}" />
</java>
<native2ascii
src="${temp.dir}/resources"
dest="${temp.dir}/resources"
encoding="UTF8"
includes="*.properties-utf8"
ext=".properties"
/>
<copy
file="${temp.dir}/resources/${dd2tu.localizedLabelBaseFilename}.properties"
tofile="${temp.dir}/resources/${dd2tu.localizedLabelBaseFilename}_en.properties"
/>
<mkdir dir="src/WebContent/js/domderrien/i18n/nls/en" />
<copy
file="src/WebContent/js/domderrien/i18n/nls/{dd2tu.localizedLabelBaseFilename}.js"
todir="src/WebContent/js/domderrien/i18n/nls/en"
/>
</target>With the TMX file as the source of thruth for the label definitions, it is just a matter of altering the value a
<prop/> tag and running the build once again to move one label definition from one programming language to another. No more error prone copy-and-paste of text between different file formats!Excerpt of the generated Java resource bundle
bundle_language=English
unit_test_sample=N/A
dd2tu_applicationName="Test Application"
dd2tu_welcomeMessage=Welcome {0}
...
x_timeStamp=20091001.1001Excerpt of the generated JavaScript resource bundle
({bundle_language:"English",
unit_test_sample:"N/A",
dd2tu_applicationName:"Test Application",
dd2tu_welcomeMessage:"Welcome ${0}",
...
x_timeStamp:"20091001.1001"})Excerpt of the generated Python class definition
# -*- coding: utf-8 -*-
dict_en = {}
def _getDictionary():
global dict_en
if (len(dict_en) == 0):
_fetchDictionary(dict_en)
return dict_en
def _fetchDictionary(dict):
dict["_language"] = "English"
dict["dd2tu_applicationName"] = "Test Application"
dict["dd2tu_welcomeMsg"] = "Welcome {0}."
...
dict["x_timestamp"] = "20091001.1001"The
TMXConverter being part of the build process and going over all localized TMX files, it generates the list of supported languages.JSP code fetching a HTML <select/> box with the list of supported languages
<span class="topCommand topCommandLabel"><%= LabelExtractor.get("rwa_loginLanguageSelectBoxLabel", locale) %></span>
<select
class="topCommand"
dojotType="dijit.form.FilteringSelect"
id="languageSelector"
onchange="switchLanguage();"
title="<%= LabelExtractor.get("rwa_loginLanguageSelectBoxLabel", locale) %>"
><%
ResourceBundle languageList = LocaleController.getLanguageListRB();
Enumeration<String> keys = languageList.getKeys();
while(keys.hasMoreElements()) {
String key = keys.nextElement();%>
<option<% if (key.equals(localeId)) { %> selected<% } %> value="<%= key %>"><%= languageList.getString(key) %></option><%
} %>
</select>The following figures illustrates the corresponding code in action.
Part of a login screen as defined with the default (English) TMX file.

Part of a login screen as defined with the French TMX file.

The two-tiers-utils library is offered with the BSD-like license. Anyone is free to use it for his own purposes. but I'll appreciate any feedback, contribution, and feature requirement.
See you on github.com ;)
“May the fork be with you.”
A+, Dom





 To start investigations on mobile application development for Compuware, I have just acquired a first Android Dev Phone, also known as G1 [1]. Last week at Google I/O, Vic Gundotra delivered an Oprah event by offering to the audience a second generation Android phone, also known as G2 or HTC Magic [2, 3]. The G1 is more limited but it is still the only Android platform legally available.
To start investigations on mobile application development for Compuware, I have just acquired a first Android Dev Phone, also known as G1 [1]. Last week at Google I/O, Vic Gundotra delivered an Oprah event by offering to the audience a second generation Android phone, also known as G2 or HTC Magic [2, 3]. The G1 is more limited but it is still the only Android platform legally available. 



 Once I decided to go with GAE, I invested a bit in improving my knowledge of Python [4], for example by looking at the WSGI specification [4] and at Django [4]. I have been impressed about the integration done by GAE people, about how easy it is to program complex steps in very few lines! My favorite part is the main function to dispatching events:
Once I decided to go with GAE, I invested a bit in improving my knowledge of Python [4], for example by looking at the WSGI specification [4] and at Django [4]. I have been impressed about the integration done by GAE people, about how easy it is to program complex steps in very few lines! My favorite part is the main function to dispatching events: In the J2EE world, with the
In the J2EE world, with the 




 Google App Engine (GAE) [1] is an open platform made available by Google to host Web applications:
Google App Engine (GAE) [1] is an open platform made available by Google to host Web applications: